[译]Python模块和包-简介

本文探讨了 Python 模块和 Python 包,这两种机制有助于模块化编程。
模块化编程是指将大型、笨重的编程任务分解为单独的、更小的、更易于管理的子任务或模块的过程。然后可以像构建块一样将各个模块拼凑在一起以创建更大的应用程序。
在大型应用程序中模块化代码有几个优点:
简单性:模块通常不会专注于手头的整个问题,而是专注于问题的一个相对较小的部分。如果您正在处理单个模块,那么您将有一个较小的问题域来解决问题。这使得开发更容易并且更不容易出错。
可维护性:模块通常设计为在不同问题域之间强制执行逻辑边界。如果模块是以最小化相互依赖的方式编写的,那么对单个模块的修改对程序的其他部分产生影响的可能性就会降低。(您甚至可以在不了解该模块之外的应用程序的情况下对该模块进行更改。)这使得由许多程序员组成的团队在大型应用程序上协同工作变得更加可行。
可重用性:在单个模块中定义的功能可以很容易地被应用程序的其他部分重用(通过适当定义的接口)。这消除了重复代码的需要。
作用域:模块通常定义一个单独的名称空间,这有助于避免程序不同区域中标识符之间的冲突。 (Python 之禅的信条之一是命名空间是一个非常棒的想法——让我们做更多这样的事情吧!)
函数、模块和包都是 Python 中促进代码模块化的构造。
Python 模块:概述
在 Python 中实际上有三种不同的方式来定义模块:
模块可以用 Python 本身编写。
模块可以用 C 语言编写并在运行时动态加载,例如
re(正则表达式)模块。内置模块本质上包含在解释器中,例如
itertools模块。
在所有三种情况下,模块的内容都以相同的方式访问:使用 import 语句。
在这里,重点将主要放在用 Python 编写的模块上。用 Python 编写的模块的妙处在于它们的构建非常简单。
您需要做的就是创建一个包含合法 Python 代码的文件,然后为该文件指定一个带有 .py 扩展名的名称。就是这样!不需要特殊的语法或巫术。
例如,假设您创建了一个名为 mod.py 的文件,其中包含以下内容:
mod.py
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
mod.py 中定义了几个对象:
s(字符串)a(列表)foo()(函数)Foo(类)
假设 mod.py 位于适当的位置(您很快就会了解更多信息),可以通过导入模块来访问这些对象,如下所示:
>>> import mod
>>> print(mod.s)
If Comrade Napoleon says it, it must be right.
>>> mod.a
[100, 200, 300]
>>> mod.foo(['quux', 'corge', 'grault'])
arg = ['quux', 'corge', 'grault']
>>> x = mod.Foo()
>>> x
<mod.Foo object at 0x03C181F0>
模块搜索路径
继续上面的例子,我们来看看 Python 执行语句时会发生什么:
import mod
当解释器执行上述 import 语句时,它会在由以下来源组装的目录列表中搜索 mod.py :
- 运行输入脚本的目录或当前目录(如果解释器正在交互式运行)
PYTHONPATH环境变量中包含的目录列表(如果已设置)。 (PYTHONPATH的格式取决于操作系统,但应模仿PATH环境变量。)- 安装 Python 时配置的依赖于安装的目录列表
生成的搜索路径可在 Python 变量 sys.path 中访问,该变量是从名为 sys 的模块获取的:
>>> import sys
>>> sys.path
['', 'C:\\Users\\john\\Documents\\Python\\doc', 'C:\\Python36\\Lib\\idlelib',
'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib',
'C:\\Python36', 'C:\\Python36\\lib\\site-packages']
注意:
sys.path的具体内容取决于安装。几乎可以肯定,上面的内容在您的计算机上看起来会略有不同。
因此,为确保找到您的模块,您需要执行以下操作之一:
- 将
mod.py放入输入脚本所在目录或当前目录,如果是交互式的 - 在启动解释器之前修改
PYTHONPATH环境变量以包含mod.py所在目录- 或者:将
mod.py放入PYTHONPATH变量中已包含的目录之一
- 或者:将
- 将
mod.py放入依赖于安装的目录之一,您可能有也可能没有写入权限,具体取决于操作系统
实际上还有一个附加选项:您可以将模块文件放在您选择的任何目录中,然后在运行时修改 sys.path 以使其包含该目录。例如,在这种情况下,您可以将 mod.py 放入目录 C:\Users\john 中,然后发出以下语句:
>>> sys.path.append(r'C:\Users\john')
>>> sys.path
['', 'C:\\Users\\john\\Documents\\Python\\doc', 'C:\\Python36\\Lib\\idlelib',
'C:\\Python36\\python36.zip', 'C:\\Python36\\DLLs', 'C:\\Python36\\lib',
'C:\\Python36', 'C:\\Python36\\lib\\site-packages', 'C:\\Users\\john']
>>> import mod
导入模块后,您可以使用模块的 __file__ 属性确定找到它的位置:
>>> import mod
>>> mod.__file__
'C:\\Users\\john\\mod.py'
>>> import re
>>> re.__file__
'C:\\Python36\\lib\\re.py'
__file__ 的目录部分应该是 sys.path 中的目录之一。
import 声明
模块内容可通过 import 语句提供给调用者。 import 语句有多种不同的形式,如下所示。
import <module_name>
最简单的形式是上面已经显示的形式:
import <module_name>
请注意,这不会使调用者直接访问模块内容。每个模块都有自己的私有符号表,作为模块中定义的所有对象的全局符号表。因此,如前所述,模块创建了一个单独的名称空间。
语句 import <module_name> 仅将 <module_name> 放入调用者的符号表中。模块中定义的对象保留在模块的私有符号表中。
对于调用者来说,只有通过点符号以 <module_name> 为前缀时才能访问模块中的对象,如下所示。
在以下 import 语句之后, mod 被放入本地符号表中。因此, mod 在调用者的本地上下文中有意义:
>>> import mod
>>> mod
<module 'mod' from 'C:\\Users\\john\\Documents\\Python\\doc\\mod.py'>
但是 s 和 foo 保留在模块的私有符号表中,并且在本地上下文中没有意义:
>>> s
NameError: name 's' is not defined
>>> foo('quux')
NameError: name 'foo' is not defined
要在本地上下文中访问,模块中定义的对象名称必须以 mod 为前缀:
>>> mod.s
'If Comrade Napoleon says it, it must be right.'
>>> mod.foo('quux')
arg = quux
可以在单个 import 语句中指定多个以逗号分隔的模块:
import <module_name>[, <module_name> ...]
from <module_name> import <name(s)>
import 语句的另一种形式允许将模块中的各个对象直接导入到调用者的符号表中:
from <module_name> import <name(s)>
执行上述语句后,可以在调用者的环境中引用 <name(s)> ,而无需使用 <module_name> 前缀:
>>> from mod import s, foo
>>> s
'If Comrade Napoleon says it, it must be right.'
>>> foo('quux')
arg = quux
>>> from mod import Foo
>>> x = Foo()
>>> x
<mod.Foo object at 0x02E3AD50>
因为这种形式的 import 将对象名称直接放入调用者的符号表中,因此任何已存在的同名对象都将被覆盖:
>>> a = ['foo', 'bar', 'baz']
>>> a
['foo', 'bar', 'baz']
>>> from mod import a
>>> a
[100, 200, 300]
甚至可以不加区别地一次性 import 模块中的所有内容:
from <module_name> import *
这会将 <module_name> 中的所有对象的名称放入本地符号表中,但以下划线 ( _ ) 字符开头的对象除外。
例如:
>>> from mod import *
>>> s
'If Comrade Napoleon says it, it must be right.'
>>> a
[100, 200, 300]
>>> foo
<function foo at 0x03B449C0>
>>> Foo
<class 'mod.Foo'>
在大规模生产代码中不一定推荐这样做。这有点危险,因为您正在将名称一起输入到本地符号表中。除非您非常了解它们并且可以确信不会发生冲突,否则您很有可能会无意中覆盖现有名称。
但是,当您只是为了测试或发现目的而使用交互式解释器时,这种语法非常方便,因为它可以让您快速访问模块必须提供的所有内容,而无需进行大量输入。
from <module_name> import <name> as <alt_name>
也可以 import 单个对象,但使用备用名称将它们输入到本地符号表中:
from <module_name> import <name> as <alt_name>[, <name> as <alt_name> …]
这使得将名称直接放入本地符号表成为可能,但避免与以前存在的名称发生冲突:
>>> s = 'foo'
>>> a = ['foo', 'bar', 'baz']
>>> from mod import s as string, a as alist
>>> s
'foo'
>>> string
'If Comrade Napoleon says it, it must be right.'
>>> a
['foo', 'bar', 'baz']
>>> alist
[100, 200, 300]
import <module_name> as <alt_name>
您还可以使用备用名称导入整个模块:
import <module_name> as <alt_name>
>>> import mod as my_module
>>> my_module.a
[100, 200, 300]
>>> my_module.foo('qux')
arg = qux
模块内容可以从函数定义中导入。在这种情况下,在调用该函数之前, import 不会发生:
>>> def bar():
... from mod import foo
... foo('corge')
...
>>> bar()
arg = corge
然而,Python 3 不允许函数内不加区别地使用 import * 语法:
>>> def bar():
... from mod import *
...
SyntaxError: import * only allowed at module level
最后,带有 except ImportError 子句的 try 语句可用于防止不成功的 import 尝试:
>>> try:
... # Non-existent module
... import baz
... except ImportError:
... print('Module not found')
...
Module not found
>>> try:
... # Existing module, but non-existent object
... from mod import baz
... except ImportError:
... print('Object not found in module')
...
Object not found in module
dir() 函数
内置函数 dir() 返回命名空间中已定义名称的列表。如果没有参数,它会在当前本地符号表中生成按字母顺序排序的名称列表:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> qux = [1, 2, 3, 4, 5]
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'qux']
>>> class Bar():
... pass
...
>>> x = Bar()
>>> dir()
['Bar', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'qux', 'x']
请注意上面对 dir() 的第一次调用如何列出解释器启动时自动定义且已在命名空间中的几个名称。当定义新名称( qux 、 Bar 、 x )时,它们会出现在 dir() 的后续调用中。
这对于识别 import 语句到底添加到命名空间中的内容非常有用:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> import mod
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'mod']
>>> mod.s
'If Comrade Napoleon says it, it must be right.'
>>> mod.foo([1, 2, 3])
arg = [1, 2, 3]
>>> from mod import a, Foo
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'a', 'mod']
>>> a
[100, 200, 300]
>>> x = Foo()
>>> x
<mod.Foo object at 0x002EAD50>
>>> from mod import s as string
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'a', 'mod', 'string', 'x']
>>> string
'If Comrade Napoleon says it, it must be right.'
当给定一个模块名称的参数时, dir() 列出模块中定义的名称:
>>> import mod
>>> dir(mod)
['Foo', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__',
'__name__', '__package__', '__spec__', 'a', 'foo', 's']
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from mod import *
>>> dir()
['Foo', '__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'a', 'foo', 's']
从脚本执行模块
任何包含模块的 .py 文件本质上也是一个 Python 脚本,并且没有任何理由不能像脚本一样执行。
这里又是上面定义的 mod.py :
mod.py
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
这可以作为脚本运行:
C:\Users\john\Documents>python mod.py
C:\Users\john\Documents>
没有错误,所以它显然有效。当然,这并不是很有趣。正如它所写的,它只定义了对象。它不会对它们做任何事情,也不会生成任何输出。
让我们修改上面的 Python 模块,以便它在作为脚本运行时生成一些输出:
mod.py
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
print(s)
print(a)
foo('quux')
x = Foo()
print(x)
现在应该更有趣了:
C:\Users\john\Documents>python mod.py
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<__main__.Foo object at 0x02F101D0>
不幸的是,现在它在作为模块导入时也会生成输出:
>>> import mod
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<mod.Foo object at 0x0169AD50>
这可能不是您想要的。模块在导入时通常不会生成输出。
如果您能够区分文件何时作为模块加载以及何时作为独立脚本运行,岂不是很好?
祈求,你们就会收到。
当 .py 文件作为模块导入时,Python 会将特殊的 dunder 变量 __name__ 设置为模块的名称。但是,如果文件作为独立脚本运行,则 __name__ (创造性地)设置为字符串 '__main__' 。利用这一事实,您可以辨别运行时的情况并相应地改变行为:
mod.py
s = "If Comrade Napoleon says it, it must be right."
a = [100, 200, 300]
def foo(arg):
print(f'arg = {arg}')
class Foo:
pass
if (__name__ == '__main__'):
print('Executing as standalone script')
print(s)
print(a)
foo('quux')
x = Foo()
print(x)
现在,如果您作为脚本运行,您将得到输出:
C:\Users\john\Documents>python mod.py
Executing as standalone script
If Comrade Napoleon says it, it must be right.
[100, 200, 300]
arg = quux
<__main__.Foo object at 0x03450690>
但如果您作为模块导入,则不会:
>>> import mod
>>> mod.foo('grault')
arg = grault
模块通常设计为能够作为独立脚本运行,以测试模块中包含的功能。这称为单元测试。例如,假设您创建了一个包含阶乘函数的模块 fact.py ,如下所示:
fact.py
def fact(n):
return 1 if n == 1 else n * fact(n-1)
if (__name__ == '__main__'):
import sys
if len(sys.argv) > 1:
print(fact(int(sys.argv[1])))
该文件可以被视为一个模块,并导入 fact() 函数:
>>> from fact import fact
>>> fact(6)
720
但它也可以通过在命令行上传递整数参数来独立运行以进行测试:
C:\Users\john\Documents>python fact.py 6
720
重新加载模块
出于效率原因,每个解释器会话仅加载一个模块一次。这对于函数和类定义来说很好,它们通常构成了模块的大部分内容。但模块也可以包含可执行语句,通常用于初始化。
请注意,这些语句仅在第一次导入模块时执行。
考虑以下文件 mod.py :
mod.py
a = [100, 200, 300]
print('a =', a)
>>> import mod
a = [100, 200, 300]
>>> import mod
>>> import mod
>>> mod.a
[100, 200, 300]
后续导入时不会执行 print() 语句。 (就此而言,赋值语句也不是,但正如 mod.a 值的最终显示所示,这并不重要。一旦进行赋值,它就会保留。)
如果您对模块进行更改并需要重新加载它,则需要重新启动解释器或使用模块 importlib 中名为 reload() 的函数:
>>> import mod
a = [100, 200, 300]
>>> import mod
>>> import importlib
>>> importlib.reload(mod)
a = [100, 200, 300]
<module 'mod' from 'C:\\Users\\john\\Documents\\Python\\doc\\mod.py'>
Python 包
假设您开发了一个非常大的应用程序,其中包含许多模块。随着模块数量的增加,如果将它们转储到一个位置,则很难跟踪所有模块。如果它们具有相似的名称或功能,则尤其如此。
您可能希望有一种对它们进行分组和组织的方法。
包允许使用点表示法对模块名称空间进行分层结构。就像模块有助于避免全局变量名称之间的冲突一样,包也有助于避免模块名称之间的冲突。
创建包非常简单,因为它利用了操作系统固有的分层文件结构。考虑以下安排:

这里有一个名为 pkg 的目录,其中包含两个模块: mod1.py 和 mod2.py 。模块的内容是:
mod1.py
def foo():
print('[mod1] foo()')
class Foo:
pass
mod2.py
def bar():
print('[mod2] bar()')
class Bar:
pass
给定此结构,如果 pkg 目录位于可以找到它的位置( sys.path 中包含的目录之一),则可以用点符号引用这两个模块( pkg.mod1 、 pkg.mod2 ) 并使用您已经熟悉的语法导入它们:
import <module_name>[, <module_name> ...]
>>> import pkg.mod1, pkg.mod2
>>> pkg.mod1.foo()
[mod1] foo()
>>> x = pkg.mod2.Bar()
>>> x
<pkg.mod2.Bar object at 0x033F7290>
from <module_name> import <name(s)>
>>> from pkg.mod1 import foo
>>> foo()
[mod1] foo()
from <module_name> import <name> as <alt_name>
>>> from pkg.mod2 import Bar as Qux
>>> x = Qux()
>>> x
<pkg.mod2.Bar object at 0x036DFFD0>
您也可以使用这些语句导入模块:
from <package_name> import <modules_name>[, <module_name> ...]
from <package_name> import <module_name> as <alt_name>
>>> from pkg import mod1
>>> mod1.foo()
[mod1] foo()
>>> from pkg import mod2 as quux
>>> quux.bar()
[mod2] bar()
从技术上讲,您也可以导入该包:
>>> import pkg
>>> pkg
<module 'pkg' (namespace)>
但这收效甚微。虽然严格来说,这是一个语法正确的 Python 语句,但它并没有做任何有用的事情。特别是,它不会将 pkg 中的任何模块放入本地命名空间中:
>>> pkg.mod1
Traceback (most recent call last):
File "<pyshell#34>", line 1, in <module>
pkg.mod1
AttributeError: module 'pkg' has no attribute 'mod1'
>>> pkg.mod1.foo()
Traceback (most recent call last):
File "<pyshell#35>", line 1, in <module>
pkg.mod1.foo()
AttributeError: module 'pkg' has no attribute 'mod1'
>>> pkg.mod2.Bar()
Traceback (most recent call last):
File "<pyshell#36>", line 1, in <module>
pkg.mod2.Bar()
AttributeError: module 'pkg' has no attribute 'mod2'
要实际导入模块或其内容,您需要使用上面显示的表单之一。
包初始化
如果包目录中存在名为 __init__.py 的文件,则在导入包或包中的模块时会调用该文件。这可用于执行包初始化代码,例如包级数据的初始化。
例如,考虑以下 __init__.py 文件:
init.py
print(f'Invoking __init__.py for {__name__}')
A = ['quux', 'corge', 'grault']
我们将此文件添加到上面示例中的 pkg 目录中:
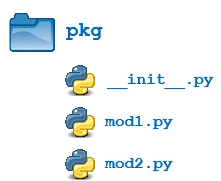
现在,当导入包时,全局列表 A 被初始化:
>>> import pkg
Invoking __init__.py for pkg
>>> pkg.A
['quux', 'corge', 'grault']
包中的模块可以通过依次导入来访问全局变量:
mod1.py
def foo():
from pkg import A
print('[mod1] foo() / A = ', A)
class Foo:
pass
>>> from pkg import mod1
Invoking __init__.py for pkg
>>> mod1.foo()
[mod1] foo() / A = ['quux', 'corge', 'grault']
__init__.py 还可以用于实现从包中自动导入模块。例如,之前您看到语句 import pkg 仅将名称 pkg 放入调用者的本地符号表中,并且不导入任何模块。但如果 pkg 目录中的 __init__.py 包含以下内容:
init.py
print(f'Invoking __init__.py for {__name__}')
import pkg.mod1, pkg.mod2
然后当您执行 import pkg 时,会自动导入模块 mod1 和 mod2 :
>>> import pkg
Invoking __init__.py for pkg
>>> pkg.mod1.foo()
[mod1] foo()
>>> pkg.mod2.bar()
[mod2] bar()
注意:许多 Python 文档都指出,创建包时,包目录中必须存在
__init__.py文件。这曾经是真的。过去,__init__.py的存在对于 Python 来说就意味着正在定义一个包。该文件可以包含初始化代码,甚至可以为空,但它必须存在。从 Python 3.3 开始,引入了隐式命名空间包。这些允许创建没有任何
__init__.py文件的包。当然,如果需要包初始化,它仍然可以存在。但不再需要了。查看什么是 Python 命名空间包,它有什么用?了解更多。
从包中导入 *
为了以下讨论的目的,先前定义的包被扩展以包含一些附加模块:

现在 pkg 目录中定义了四个模块。它们的内容如下所示:
mod1.py
def foo():
print('[mod1] foo()')
class Foo:
pass
mod2.py
def bar():
print('[mod2] bar()')
class Bar:
pass
mod3.py
def baz():
print('[mod3] baz()')
class Baz:
pass
mod4.py
def qux():
print('[mod4] qux()')
class Qux:
pass
那有什么作用?
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
哼。不多。您可能期望(假设您有任何期望)Python 会深入到包目录中,找到它能找到的所有模块,并将它们全部导入。但正如您所看到的,默认情况下不会发生这种情况。
相反,Python 遵循此约定:如果包目录中的 __init__.py 文件包含名为 __all__ 的列表,则在遇到语句 from <package_name> import * 时,它被视为应导入的模块列表。
对于本示例,假设您在 pkg 目录中创建一个 __init__.py ,如下所示:
pkg/init.py
__all__ = [
'mod1',
'mod2',
'mod3',
'mod4'
]
现在 from pkg import * 导入所有四个模块:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'mod1', 'mod2', 'mod3', 'mod4']
>>> mod2.bar()
[mod2] bar()
>>> mod4.Qux
<class 'pkg.mod4.Qux'>
使用 import * 仍然不被认为是一种很好的形式,对于包来说比对于模块来说更是如此。但此功能至少使包的创建者可以对指定 import * 时发生的情况进行一些控制。 (事实上,它提供了完全禁止它的功能,只需完全拒绝定义 __all__ 即可。正如您所看到的,包的默认行为是不导入任何内容。)
顺便说一句, __all__ 也可以在模块中定义,并具有相同的目的:控制使用 import * 导入的内容。例如,修改 mod1.py 如下:
pkg/mod1.py
__all__ = ['foo']
def foo():
print('[mod1] foo()')
class Foo:
pass
现在,来自 pkg.mod1 的 import * 语句将仅导入 __all__ 中包含的内容:
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__']
>>> from pkg.mod1 import *
>>> dir()
['__annotations__', '__builtins__', '__doc__', '__loader__', '__name__',
'__package__', '__spec__', 'foo']
>>> foo()
[mod1] foo()
>>> Foo
Traceback (most recent call last):
File "<pyshell#37>", line 1, in <module>
Foo
NameError: name 'Foo' is not defined
foo() (函数)现在定义在本地命名空间中,但 Foo (类)不是,因为后者不在 __all__ 中。
总之,包和模块都使用 __all__ 来控制指定 import * 时导入的内容。但默认行为有所不同:
- 对于包来说,当
__all__未定义时,import *不会导入任何内容。 - 对于模块,当未定义
__all__时,import *会导入所有内容(除了——你猜对了——以下划线开头的名称)。
子包
包可以包含任意深度的嵌套子包。例如,我们对示例包目录再做一个修改,如下:
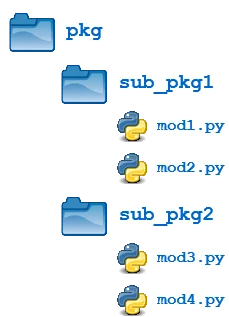
四个模块( mod1.py 、 mod2.py 、 mod3.py 和 mod4.py )的定义如前。但现在,它们不再被集中到 pkg 目录中,而是分成两个子包目录: sub_pkg1 和 sub_pkg2 。
导入仍然与之前所示的一样。语法类似,但使用额外的点符号将包名称与子包名称分开:
>>> import pkg.sub_pkg1.mod1
>>> pkg.sub_pkg1.mod1.foo()
[mod1] foo()
>>> from pkg.sub_pkg1 import mod2
>>> mod2.bar()
[mod2] bar()
>>> from pkg.sub_pkg2.mod3 import baz
>>> baz()
[mod3] baz()
>>> from pkg.sub_pkg2.mod4 import qux as grault
>>> grault()
[mod4] qux()
此外,一个子包中的模块可以引用同级子包中的对象(如果同级子包包含您需要的某些功能)。例如,假设您想从模块 mod3 中导入并执行函数 foo() (在模块 mod1 中定义)。您可以使用绝对导入:
pkg/sub__pkg2/mod3.py
def baz():
print('[mod3] baz()')
class Baz:
pass
from pkg.sub_pkg1.mod1 import foo
foo()
>>> from pkg.sub_pkg2 import mod3
[mod1] foo()
>>> mod3.foo()
[mod1] foo()
或者您可以使用相对导入,其中 .. 指的是上一级的包。从子包 sub_pkg2 中的 mod3.py 中,
..计算父包 (pkg),并且..sub_pkg1计算为父包的子包sub_pkg1。
pkg/sub__pkg2/mod3.py
def baz():
print('[mod3] baz()')
class Baz:
pass
from .. import sub_pkg1
print(sub_pkg1)
from ..sub_pkg1.mod1 import foo
foo()
>>> from pkg.sub_pkg2 import mod3
<module 'pkg.sub_pkg1' (namespace)>
[mod1] foo()
结论
在本教程中,您涵盖了以下主题:
如何创建 Python 模块
Python 解释器搜索模块的位置
如何使用
import语句获取对模块中定义的对象的访问权限如何创建可作为独立脚本执行的模块
如何将模块组织成包和子包
如何控制包初始化
这有望让您更好地了解如何访问 Python 中可用的许多第三方和内置模块中可用的功能。
此外,如果您正在开发自己的应用程序,创建自己的模块和包将帮助您组织和模块化代码,从而使编码、维护和调试更加容易。
如果您想了解更多信息,请查看 Python.org 上的以下文档:
快乐的 Python!